来自: https://www.qcloud.com/community/article/164816001481011945
最近研发的项目对DB依赖比较重,梳理了这段时间使用MySQL遇到的8个比较具有代表性的问题,答案也比较偏自己的开发实践,没有DBA专业和深入,有出入的请使劲拍砖!…
MySQL读写性能是多少,有哪些性能相关的配置参数?
MySQL负载高时,如何找到是由哪些SQL引起的?
如何针对具体的SQL做优化?
SQL层面已难以优化,请求量继续增大时的应对策略?
MySQL如何做主从数据同步?
如何防止DB误操作和做好容灾?
该选择MySQL哪种存储引擎,Innodb具有什么特性?
MySQL内部结构有哪些层次?
1.MySQL读写性能是多少,有哪些性能相关的重要参数?
这里做了几个简单压测实验
机器:8核CPU,8G内存
表结构(尽量模拟业务):12个字段(1个bigint(20)为自增primary key,5个int(11),5个varchar(512),1个timestamp),InnoDB存储引擎。
实验1(写):insert => 6000/s
前提:连接数100,每次insert单条记录
分析:CPU跑了50%,这时磁盘为顺序写,故性能较高
实验2(写):update(where条件命中索引) => 200/s
前提:连接数100,10w条记录,每次update单条记录的4个字段(2个int(11),2个varchar(512))
分析:CPU跑2%,瓶颈明显在IO的随机写
实验3(读):select(where条件命中索引) => 5000/s
前提:连接数100,10w条记录,每次select单条记录的4个字段(2个int(11),2个varchar(512))
分析:CPU跑6%,瓶颈在IO,和db的cache大小相关
实验4(读):select(where条件没命中索引) => 60/s
前提:连接数100,10w条记录,每次select单条记录的4个字段(2个int(11),2个varchar(512))
分析:CPU跑到80%,每次select都需遍历所有记录,看来索引的效果非常明显!
几个重要的配置参数,可根据实际的机器和业务特点调整
max_connecttions:最大连接数
table_cache:缓存打开表的数量
key_buffer_size:索引缓存大小
query_cache_size:查询缓存大小
sort_buffer_size:排序缓存大小(会将排序完的数据缓存起来)
read_buffer_size:顺序读缓存大小
read_rnd_buffer_size:某种特定顺序读缓存大小(如order by子句的查询)
PS:查看配置方法: show variables like '%max_connecttions%';
2.MySQL负载高时,如何找到是由哪些SQL引起的?
方法:慢查询日志分析(MySQLdumpslow)
慢查询日志例子,可看到每个慢查询SQL的耗时:
| |
日志显示该查询用了1.958秒,返回254786行记录,一共遍历了254786行记录。及具体的时间戳和SQL语句。
使用MySQLdumpslow进行慢查询日志分析
MySQLdumpslow -s t -t 5 slow_log_20140819.txt
输出查询耗时最多的Top5条SQL语句
-s:排序方法,t表示按时间 (此外,c为按次数,r为按返回记录数等)
-t:去Top多少条,-t 5表示取前5条
执行完分析结果如下:
| |
以第1条为例,表示这类SQL(N可以取很多值,这里MySQLdumpslow会归并起来)在8月19号的慢查询日志内出现了1076100次,总耗时99065秒,总返回440058825行记录,有28个客户端IP用到。
通过慢查询日志分析,就可以找到最耗时的SQL,然后进行具体的SQL分析了
慢查询相关的配置参数
log_slow_queries:是否打开慢查询日志,得先确保=ON后面才有得分析
long_query_time:查询时间大于多少秒的SQL被当做是慢查询,一般设为1S
log_queries_not_using_indexes:是否将没有使用索引的记录写入慢查询日志
slow_query_log_file:慢查询日志存放路径
3.如何针对具体的SQL做优化?
使用Explain分析SQL语句执行计划
| |
如上面例子所示,重点关注下type,rows和Extra:
type:使用类别,有无使用到索引。结果值从好到坏:… > range(使用到索引) > index > ALL(全表扫描),一般查询应达到range级别
rows:SQL执行检查的记录数
Extra:SQL执行的附加信息,如"Using index"表示查询只用到索引列,不需要去读表等
使用Profiles分析SQL语句执行时间和消耗资源
| |
SQL优化的技巧 (只提一些业务常遇到的问题)
最关键:索引,避免全表扫描。
对接触的项目进行慢查询分析,发现TOP10的基本都是忘了加索引或者索引使用不当,如索引字段上加函数导致索引失效等(如
where UNIX_TIMESTAMP(gre_updatetime)>123456789)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15+----------+------------+---------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------+ | 1 | 0.00024700 | select * from mytable where id=100 | | 2 | 0.27912900 | select * from mytable where id+1=101 | +----------+------------+---------------------------------------+ 另外很多同学在拉取全表数据时,喜欢用select xx from xx limit 5000,1000这种形式批量拉取,其实这个SQL每次都是全表扫描,建议添加1个自增id做索引, 将SQL改为select xx from xx where id>5000 and id<6000; +----------+------------+-----------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------------------------+ | 1 | 0.00415400 | select * from mytable where id>=90000 and id<=91000 | | 2 | 0.10078100 | select * from mytable limit 90000,1000 | +----------+------------+-----------------------------------------------------+ 合理用好索引,应该可解决大部分SQL问题。当然索引也非越多越好,过多的索引会影响写操作性能只select出需要的字段,避免select
1 2 3 4 5 6+----------+------------+-----------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------------------------+ | 1 | 0.02948800 | select count(1) from ( select id from mytable ) a | | 2 | 1.34369100 | select count(1) from ( select * from mytable ) a | +----------+------------+-----------------------------------------------------+尽量早做过滤,使Join或者Union等后续操作的数据量尽量小
把能在逻辑层算的提到逻辑层来处理,如一些数据排序、时间函数计算等
…….
PS:关于SQL优化,已经有足够多文章了,所以就不讲太全面了,只重点说自己1个感受:索引!基本都是因为索引!
4.SQL层面已难以优化,请求量继续增大时的应对策略?
下面是我能想到的几个方法,每个方法又都是一篇大文章了,这里就不展开
分库分表
使用集群(master-slave),读写分离
增加业务的cache层
使用连接池
5.MySQL如何做主从数据同步?
复制机制(Replication)
master通过复制机制,将master的写操作通过binlog传到slave生成中继日志(relaylog),slave再将中继日志redo,使得主库和从库的数据保持同步
复制相关的3个MySQL线程
slave上的I/O线程:向master请求数据
master上的Binlog Dump线程:读取binlog事件并把数据发送给slave的I/O线程
slave上的SQL线程:读取中继日志并执行,更新数据库
属于slave主动请求拉取的模式
实际使用可能遇到的问题
数据非强一致:CDB默认为异步复制,master和slave的数据会有一定延迟(称为主从同步距离,一般 < 1s)
主从同步距离变大:可能是DB写入压力大,也可能是slave机器负载高,网络波动等原因,具体问题具体分析
相关监控命令
show processlist:查看MySQL进程信息,包括3个同步线程的当前状态
show master status :查看master配置及当前复制信息
show slave status:查看slave配置及当前复制信息
6.如何防止DB误操作和做好容灾?
业务侧应做到的几点:
重要DB数据的手工修改操作,操作前需做到2点:1 先在测试环境操作 2 备份数据
根据业务重要性做定时备份,考虑系统可承受的恢复时间
进行容灾演练,感觉很必要
MySQL备份和恢复操作
1.备份:使用MySQLdump导出数据
| |
2.恢复:导入备份数据
MySQL -uxxx -p xxxx < mytable.20140921.bak.sql
3.恢复:导入备份数据之后发送的写操作。先使用MySQLbinlog导出这部分写操作SQL(基于时间点或位置)
如导出2014-09-21 09:59:59之后的binlog:
| |
如导出起始id为123456之后的binlog:
| |
最后把要恢复的binlog导入db
MySQL -uxxxx -p xxxx < binlog.data.sql
7.该选择MySQL哪种存储引擎,Innodb具有什么特性?
存储引擎简介
插件式存储引擎是MySQL的重要特性,MySQL支持多种存储引擎以满足用户的多种应用场景
存储引擎解决的问题:如何组织MySQL数据在介质中高效地读取,需考虑存储机制、索引设计、并发读写的锁机制等
MySQL5.0支持的存储引擎有MyISAM、InnoDB、Memory、Merge等
**MyISAM和InnoDB的区别(只说重点了)
InnoDB
MySQL5.5之后及CDB的默认引擎。
支持行锁:并发性能好
支持事务:故InnoDB称为事务性存储引擎,支持ACID,提供了具有提交、回滚和崩溃恢复能力的事务安全
支持外键:当前唯一支持外键的引擎
MyISAM
MySQL5.5之前默认引擎
支持表锁:插入+查询速度快,更新+删除速度慢
不支持事务
使用show engines可查看当前MySQL支持的存储引擎详情

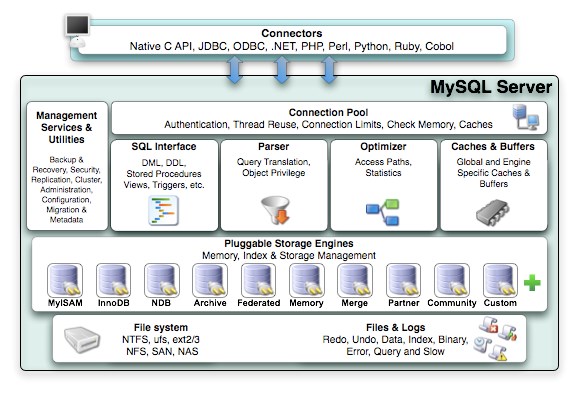
8.MySQL内部结构有哪些层次?
非专业DBA,这里只简单贴个结构图说明下。MySQL是开源系统,其设计思路和源代码都出自大牛之手,有空可以学习下。